一个月前,我在 Github 开源了 ChatLab。当时的初衷是做一个有趣的聊天记录分析工具,没想到短短 30 天内,收到了 3500 位开发者的 Star 和无数用户的反馈。
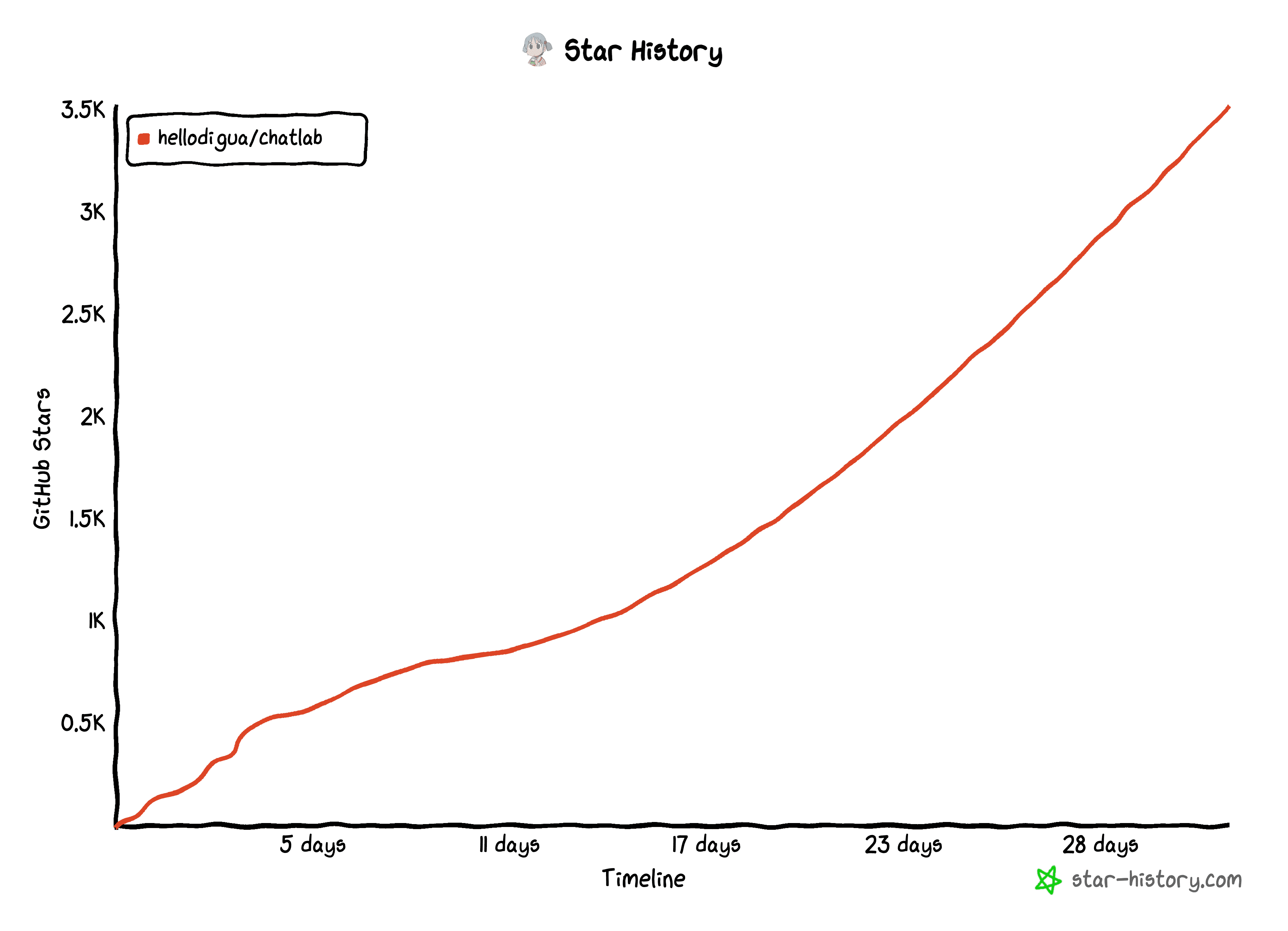
说实话,做梦都没想到过自己的项目会如此受欢迎(ÒωÓױ)
从有趣开始
我是一个拖延症很重的人。早在 2022 年,我就有了分析聊天记录的想法,脑子里塞满了各种 idea。然而,在手动造轮子时代,一个解析聊天记录的正则表达式都会因为各种BUG,花费我一整天。
当时很多功能虽然有了计划,但是限于执行力差(其实就是菜→_→),并没有实现出来,开发一周后便战略性放弃(逃。
时光飞逝,转眼间来到了2025年底,三年过去,虽然我的技术能力没有任何增长,但是——AI!我们有了 AI!

恰逢年底,我在小红书看到一个 AI 比赛,主办方希望大家能利用本地的 AI 能力来开发有一些有趣的项目。
比赛需要本地化,还需要有趣,而且要安全,我瞬间想起了那个尘封三年的念头。
这一次,在 AI 的加持下,仅两周时间,没有手写一行代码就完成了 ChatLab 的初版。每完成一个新功能,就迫不及待地把分析结果发到群里,大家为各种分析结果欢乐了好久。
最终比赛没有获奖,但群友们的好评已是我心目中的最佳奖品。
决定产品化
比赛结束,我开始思考,就这样就结束了吗?
Gtihub上类似的分析工具有很多,但大部分都太技术向了,使用还需要配环境、跑脚本,为什么不继续做下去,把这种分析能力简单化,让所有人都能使用?
即使是不懂技术的人,也理应拥有轻松拆解并重拾属于自己的社交记忆的权力。
在想好要做什么之后,我注册了一个域名:chatlab.fun
- ChatLab:意为聊天记录分析实验室
- .fun:希望它有趣,而不是一个沉闷的分析工具
花了一周打磨好官网和客户端后,ChatLab 在 12月23日 开源了。
- 因为希望能服务于所有人,所以产品免费
- 因为希望被全世界的开发者监督和共创,所以代码开源
- 因为希望能最大限度保证数据的隐私,所以软件运行本地化
最终,这个项目找到了它的定位,我把它放在了 Github 的介绍:
ChatLab 是一个免费、开源、本地化的,专注于分析聊天记录的应用。通过 AI Agent 和灵活的 SQL 引擎,你可以自由地拆解、查询甚至重构你的社交数据。
高速迭代的一个月
开源第一天,我在 V2EX 和 Linxo Do 各发了一篇帖子,当天的 star 就破了百。(再次感谢各位V友和佬友
之后,我几乎没再主动推广,ChatLab 就自发地在各个平台传播了起来,用户的各种需求也接踵而至。
于是还没来得及开心,就卷入了不断迭代的日子,短短 30 天,版本号从 v0.1.0 狂飙到了 v0.7.0。
在这一个月内,除了睡觉和本职工作,全部精力都投入到了 ChatLab 上:
- 完成了全量的国际化适配,支持了中英文的双语切换
- 支持了更多聊天软件,WhatsApp、Discord、Instagram 等陆续支持了分析
- 接入了更多 AI 模型,优化了 AI 交互逻辑,并支持了对各种分析结果的导出
- 上线了 SQL 实验室、自定义筛选等新功能,增加了更多维度的可视化图表
本以为会这样一直迭代下去,但是最近发生了一件事:某鹅法务向 Github 和相关作者发了律师函,最终下架了一批相关的开源项目。
消息一出,很多朋友跑来问我,这件事会影响 ChatLab 吗?
实际上,在开始设计功能和架构的时候,它就非常注重合规性:
首先,ChatLab 的核心定位是分析数据,而不是获取数据,它不支持对聊天软件进行数据爬取。
其次,ChatLab 是一个本地化的软件,它不会上传任何数据,所有的数据都存在本地。
最后,ChatLab 有一套自己的格式规范,用户需要将对应的聊天记录转换为 ChatLab 的聊天格式。
通过这些措施,ChatLab 得以成为一个和其他任何软件无关的,独立的第三方项目。
虽然风险较低,但当这个新闻最终被推到了风口浪尖时,我仍然担心隐私问题,所以停下开发,并开始思考:作为聊天分析工具的开发者,我们处理数据隐私的权利边界,到底在哪里?
数据隐私和归属权
很多时候,我们谈论隐私保护,潜台词是“数据属于我,我不想让别人看”。
可惜,对于目前某些主流的社交软件而言,你的聊天记录并不属于你。
对于聊天记录,你仅拥有“查看权”,而平台对其加密存储与导出封锁,在用户与数据之间筑起了一道深不见底的屏障。
一旦亲人逝去,或者手机丢失没来得及备份,这些聊天记录可能就永远丢失了。
我能部分理解平台出于安全合规、自保或维护生态的考量而选择收紧边界,但我觉得,隐私和安全不应成为剥夺用户数据自主权的万能借口。
聊天记录的本质是用户生活的投射,每一条记录背后都流淌着真实的体温与情感。
对于用户而言,这些早已不是简单的数据和文件,它是长达十年的社交关系,是亲人珍贵的语音,更是我们外挂在数字世界的情感大脑。
诚然,平台会担心开放可能被灰黑产利用,或是导致普通用户在不经意间泄露敏感信息。为了保护绝大多数用户的安全,严密加密确实有必要。但安全不代表封死所有出口,平台至少应该为有需求的用户,留下一条合法、安全、受控的导出渠道。
当我们在抖音、小红书、B站等平台搜索时,会发现有非常多的用户有导出聊天记录的诉求:亲人去世留作回忆、法律取证、情侣和朋友的情感寄托、工作记录留痕等等,用户在网络上都发出了大量的需求声音,进而催生了各种开源或不开源的导出工具。
当你打开各个购物软件,搜索相关的聊天记录导出和恢复工具,很多商品的销量都很高。如果这些非官方的闭源工具中藏着恶意脚本,那才是真正的安全隐患。
用户为了拿回属于自己的记忆,不得不游走在这些充满风险的边缘地带,这本身就很荒谬。
而这,本应该是平台作为互联网基础设施应尽的义务。
这个项目的未来在哪里?
为了找到答案,我花了一天时间,调查了全世界主流聊天软件对“数据导出”的态度:
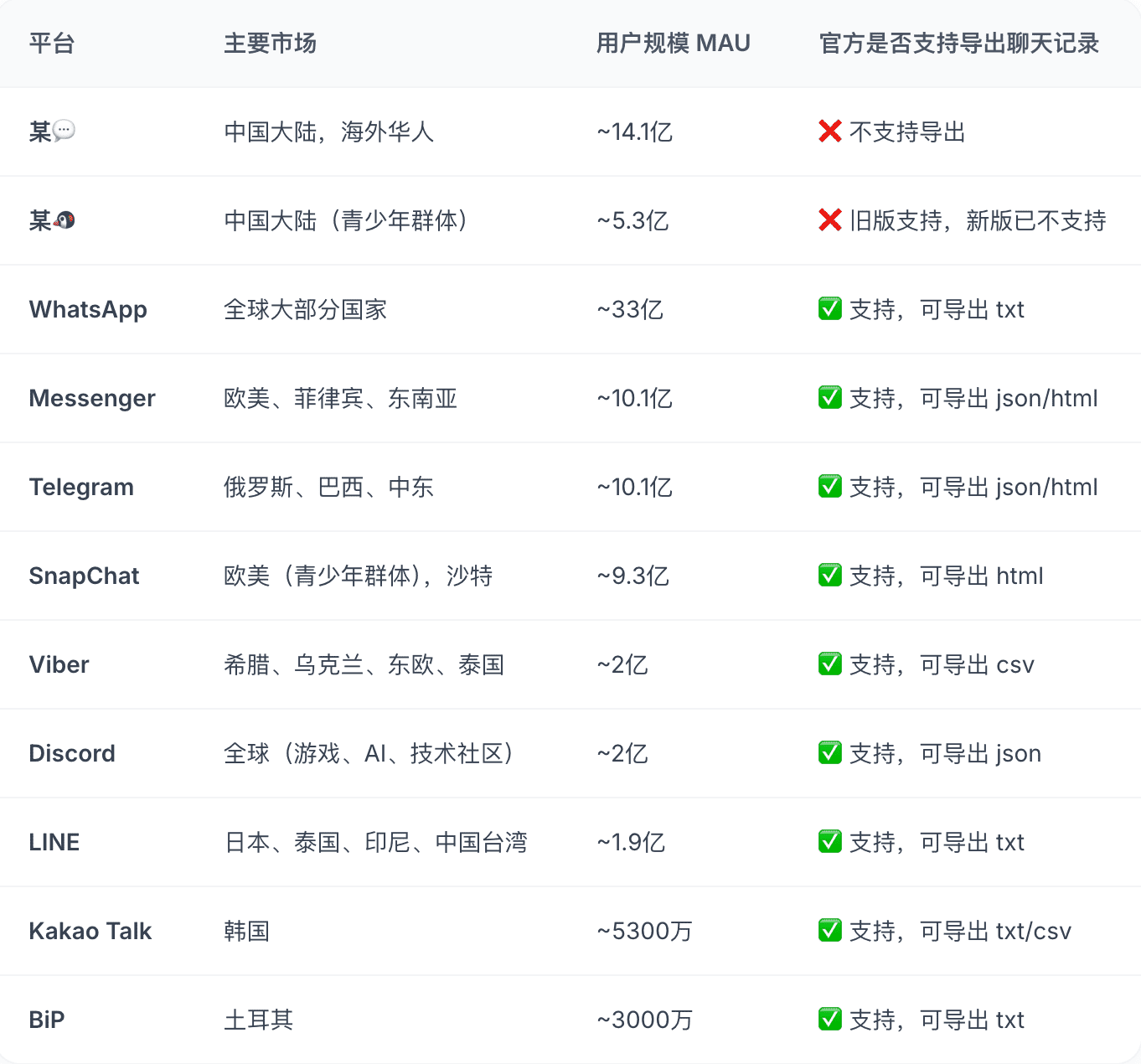
放眼全世界,大多数社交软件都提供了清晰、合法的导出功能,它们认可用户对个人数据的处置权与知情权。
调查的结果成了我继续维护下去的最大勇气。
即便未来因为某些不可抗力无法服务一部分用户,ChatLab 也会以其他方式继续存在,去支持那些尊重用户数据主权、允许记录导出的软件平台们。
同时,为了保护这个尚在初期的项目,避免以后的纷争, ChatLab 会一直遵循这些原则:
- 对内,ChatLab 的开发底线始终是做一个纯粹、中立的本地分析工具,它不包含任何破解、解密或上传的逻辑代码,它的本质就是一个 excel/SQL 查询工具。
- 对用户,我们必须向用户强调,所有分析行为必须建立在合法授权、规范获取的基础之上。
- 对巨头,我只是一个普通的开发者,无意与大厂对抗。如果未来某一天,ChatLab 依然被判定为越界并收到正式函件,我会迅速下架相关内容。
但说句老实话,ChatLab 的技术原理很简单,我能花两周写出来,那全世界至少 1000 万开发者都能开发出来同样的项目。
未来随着 AI 更加强大,也许每个普通人都能做到。
只要这些厂商仍然坚持「你的聊天记录不属于你」,那么网络上就仍然会源源不断地涌现出新的火种。
毕竟,人类想要掌控自己社交记忆的本能,是律师函删不掉的。
仍然在坚持维护的开发者们
在开发过程中,我也联系过目前在 GitHub 上继续维护导出项目的开发者,让我大受震撼的是,他们居然是两个还在读书的未成年高中生。
他们的纯粹远超我的想象:
不收取任何费用,甚至还在用每个月不多的零花钱,自费开通 AI Coding 会员来辅助项目开发。
每天放学后利用业余时间,回复用户的各种琐碎问题,以及迭代代码。
在这些少年眼里,代码不是获利的工具,而是一种本能的表达。
实际上我发现,技术正在迅速的低龄化和普及化,以往需要专业知识才能完成的复杂项目,现在很多初中生、高中生就可以完成。
当问他们为什么要开发时:
某饺: 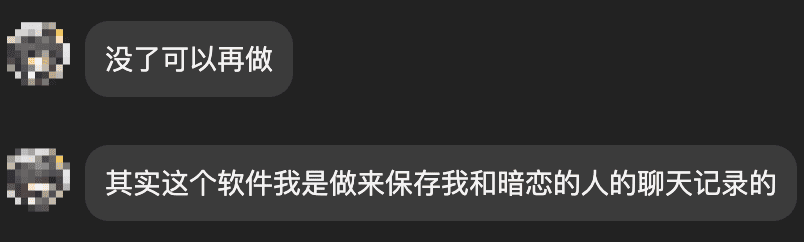
某c: 
(初衷太朴素了🤣
当庞然大物们在为了利益封锁各自平台的内容生态时,试图无偿给用户一个手电筒照亮自家地窖的,是一群勇敢的00后/10后们。
(在此预祝他们高考顺利
ChatLab的未来
虽然比较悲观,但如果 ChatLab 有未来的话,那么接下来的更新计划是:
AI Agent的全面迭代
又要暴露自己菜的事实了,目前的 ChatLab 在 AI 功能上还处于早期阶段。
想要让 AI 真正做到聪明,还需要在底层架构上完成几次迭代:
- RAG架构:除了对话模型,支持同时接入向量化模型与重排模型,让 Agent 不再局限于单次会话上下文
- 动态记忆层:引入类似 mem0 的本地化记忆方案,为 ChatLab 增加持久记忆能力,让 AI 能逐渐记住人际关系网、或者是提到的重要往事,从而解决长上下文检索下的信息遗忘问题
- Agent 系统:引入子 Agent 代理,通过任务规划与工具调用,让专门负责 SQL 查询、情感分析与摘要生成的多个小专家协作,深度挖掘出数据背后的洞察
- Skill 能力:支持用户分享自己编写的“SQL 模板 + AI 分析逻辑”组合。比如“群聊成分分析”、“群聊当日聊天内容总结” 还是 “年度情感洞察”,都可以作为一个独立的 Skill 一键复用
- Prompt 社区:支持针对不同分析风格的系统提示词市场,可以为 AI Agent 换上不同的回答风格和方式,让分析结果不再是冷冰冰的报告,而是带有性格的文字
视觉化图表库
这是接下来策划的一个全新模块,不同于枯燥的统计表,它将专注于高颜值的图形效果,通过关系网络图谱、活跃度脉动流、个性化的年度报告等等,把枯燥的记录变成可展示的图形界面。
对于数据的表达方式,我希望它不仅是AI分析的枯燥文字结果,更是可感知的、具备美感的艺术作品。
构建更开放的生态
- 支持更多的语言:繁体中文、日语、韩语、俄语、法语等
- 兼容更多的聊天软件平台:Messenger、SnapChat、iMessage、LINE等
- 建立一套通用的 聊天记录数据交换格式规范,让开发者不再各自为战
- 插件系统:把导入能力、分析能力、图形能力抽象为插件,让每一位有想法的开发者或深度用户,都可以定义属于自己的使用体验
守住底线:隐私化
无论功能如何进化,ChatLab 的核心底线不会改变:核心数据始终留存本地,不会上传云端。
当然,AI功能例外 🌚
↑这其实是个很尴尬的问题,对大部分用户来说,本地电脑性能不够,想要获得最佳的分析体验,还是需要配置在线大模型API。
在线大模型的问题显而易见:它的逻辑注定了部分聊天记录需要上传至模型服务商,如果这些记录中夹杂了隐私信息,就会面临很大风险。
目前的想法是,提供三重保障:
- 全栈本地化支持:持续优化对 Ollama 等本地模型工具的适配,让有能力、有需求的用户,仍然可以配置本地 LLM 等模型,实现彻底地断网分析。
- 脱敏规则引擎:针对使用云端 API 的用户,计划开发本地预处理脱敏系统。在数据离开电脑前,本地化引擎根据预设规则,自动识别并模糊化手机号、密码、token 等敏感信息,同时也支持用户自己查询设置黑名单。确保即便在大模型进行语义分析时,现实身份依然被妥善封存在本地。
- 反复的隐私告知:我们不会把隐私说明藏在深层的角落里。从下载软件前到首次运行,再到第一次调用 AI 能力,都会反正提醒,确保每一位用户能在充分知情的情况下(尤其是非技术背景的小白用户),再做出自己的选择。
最后,如果有必要,也会探索更安全的本地加密存储方案,确保在享受分析服务的同时,不必担心隐私崩塌。
开源软件的长期主义
一个开源项目到底能持续维护多久?
我在 2017 年的时候开发了自己的第一个开源项目 vue-danmaku,在过去的 8 年时间里,它一直保持着迭代与维护。
虽然没有1分钱的收入,但是它作为自己在开源世界的个人名片,让我觉得自己对世界而言并不是一无是处。
(当时的我真没想到它能持续维护8年
vue-danmaku也给我带来了回报:很多次面试时,面试官都对这个项目感兴趣,并(可能有一部分原因)因为它通过了这一轮面试。
面试官看中的,或许未必是代码本身,而是横跨 8 年的 commit 记录代表的长期主义。
毕竟这么长时间,最开始的新鲜感早就没了,剩下的全是修修补补和解决 issue ╮(╯_╰)╭
但既然有人在用,就时不时维护着,最后反会成为一种无需自证的信用证明。
对于 ChatLab 而言,我没法确定自己能陪它走多远,但我希望它能延续这种生命力。
不过幸运的一点是,它的功能都是在本地运行,这让它少了一些服务成本的压力,哪怕我因为精力有限很久不更新,它也不存在因为欠费而关停的风险。
只要你的电脑还能开机,这个工具就永远属于你,这是它能长期活下去的最大底气。
最后
它并不是一个人的项目,有很多朋友在开发过程中给了无私帮助。
HZFE 的家人们,动森初级玩家、夜喵、原味板烧鸡腿堡等朋友帮我完成了测试,好宅进行了隐私方面的提示和辅导,小鱼借给我苹果开发者会员,征询了群友们意见后,同意了将群聊结果作为示例图宣传。
某c和某饺在项目刚发布就在他们的项目推荐了 ChatLab,某F为 Windows 版优化提供了不少帮助。
还有很多朋友,限于篇幅不再一一列举,同样很感谢他们。
也很感谢每一位贡献代码、提出 BUG 和建议、或是在 Github 点亮了一颗 Star 的朋友。
在这个快速迭代、甚至连记忆都可以被算法定义的时代,我们太需要一块属于自己的、不被打扰的数字自留地。
代码也许会过时,项目也许会死去,但当你多年后重新回顾和家人朋友们的语音、照片和文字,看到那些闪闪发光的过往,你会发现:那些被记录的瞬间,才是我们真实活过的证据。